Java集合原理和底層數據結構總結
先放一張集合的層級圖
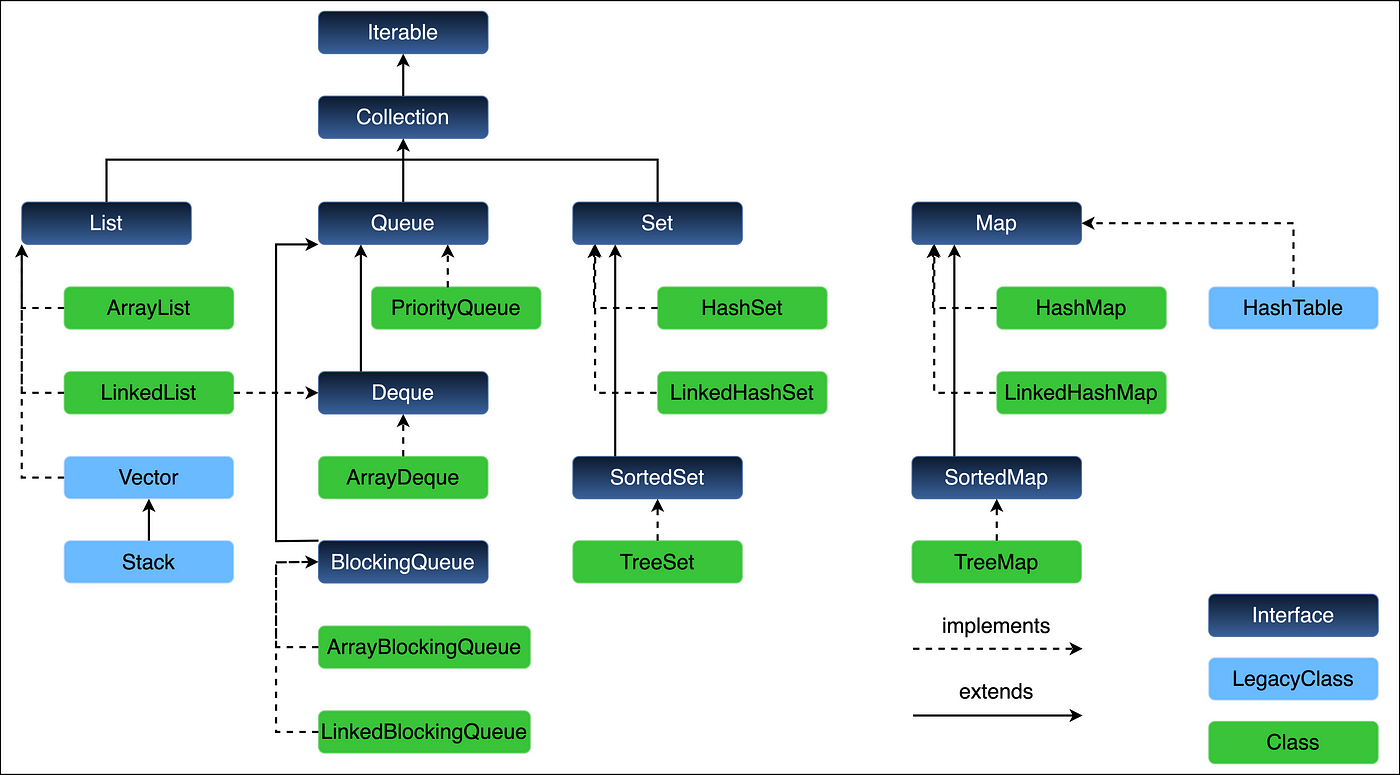
List
List的特點是順序性,可重複性。
ArrayList
允許任何元素包括null。和Vector相比不是線程安全的。在必要時可以用Collections.synchronizedList()來將ArrayList轉換成線程安全的List
1 | List list = Collections.synchronizedList(new ArrayList()); |
底層維護了一個Object數組用來存儲元素。
1 | transient Object[] elementData; |
定義了一個grow()方法,當調用一繫列重載的add方法時,會根據是否到達capacity來調用grow()以保証ArrayList的容量滿足需求。
PriorityQueue
PriorityQueue通過維護了一個小頂堆來保証首元素是所有元素中最小的元素,最小取決於元素實現的Comparator或者Comparable。它也提供了一個構造函數以便傳入自定義的Comparator來決定排序的順序。
1 | public PriorityQueue(Comparator<? super E> comparator) |
1 | transient Object[] queue; |
這裡的modCount是一個用來記錄restructure(添加,刪除或改變集合中元素的排列順序)次數的變量,當創建了iterator之後如果modCount髮生了變化就會拋出ConcurrentModificationException異常。
ProrityQueue不允許插入null值。
插入,刪除頭部元素操作的時間複雜度爲O(logn)。查找和刪除指定元素的時間複雜度爲O(n)。
插入元素的操作
- 超出
capacity,需要無論在什麼位置插入,都需要O(n)將原數組複製到更大的數組中,再用O(1)進行插入操作,所以時間複雜度爲O(n)。 - 沒有超出
capacity- 在尾部插入
O(1) - 在其他位置
O(n)
- 在尾部插入
刪除元素的操作
- 刪除尾部元素
O(1) - 刪除其他位置
O(n)
RandomAccess
ArrayList實現了RandomAccess接口,表示可以隨機訪問,即可以根據下標訪問元素,因爲底層是一個數組,數組天生具備隨機訪問的能力。
LinkedList
LinkedList在底層維護了一個雙向鏈表來存儲數據
1 | transient int size = 0; |
1 | private static class Node<E> { |
每一個LinkedList包含兩個指針分別指向鏈表的頭節點和末節點。
RandomAccess
顯然,LinkedList並不支持隨機訪問,因爲鏈表在查找元素時需要線性遍曆整個鏈表,時間複雜度爲O(n),不能做到像數組那樣O(1)的直接訪問。
Methods
對於插入和刪除操作主要有兩個繫列
- add and remove
addFirst(),addLast()removeFirst(),removeLast()
- offer and poll
offerFirst(),offerLast()pollFirst(),pollLast()
主要的區別的在於1在remove的時候如果list爲空會拋出異常而2的poll隻會返回false。
其實當調用2繫列方法的時候實際上也會調用1的對應方法,如
1 | public boolean offerLast(E e) { |
在鏈表頭和尾插入或刪除的時間複雜度爲O(1)。在其他位置插入或刪除的時間複雜度均爲O(n)。
Queue
隊列的最大特點是實現了FIFO(First In First Out)的數據結構,所以很適合在有順序需求的場景下應用。
在Queue接口下還有一個子接口Deque,在Queue的基礎上實現了雙端隊列的邏輯,同時可以用來模擬Stack。
可以用ArrayDeque或者LinkedList來實現Queue接口,但相比之下ArrayDeque不允許null值。值得一提的是當用來模擬Stack的時候使用ArrayDeque比Stack效率高,同時在用作隊列時效率比LinkedList高。
ArrayDeque
ArrayDeque的底層維護着一個循環數組,這就是爲什麼他可以被用作雙端隊列。除了remove一繫列的方法和contains,其他的方法都保持在常數級別的複雜度。
1 | transient Object[] elements; |
在執行添加操作的時候,隻需要移動頭指針或者尾指針即可。
Set
Set主要應用場景是去重。
HashSet
HashSet的底層其實維護着一個HashMap,隻不過插入HashSet中的所有元素的Value全部都被設置爲了一個Object
1 | private static final Object PRESENT = new Object(); |
當執行add()操作時,就會講value設置爲上麵這個`PRESENT
1 | public boolean add(E e) { |
TreeSet
TreeSet底層維護的是一個紅黑樹,可以實現插入元素的自動排序。
Comparator and Comparable
自動排序依賴的是元素實現的Comparator或者Comparable接口,在構造方法中也可以將實現的Comparator接口作爲參數傳入,並按照實現的接口的方式對TreeSet內的元素進行排序。
1 | TreeSet(Comparator<? super E> comparator) |
假如TreeSet的元素必須實現Comparator或者Comparable接口,或者在構造方法中傳入一個Comparator的實現類。否則在向TreeSet中插入元素的時候會髮生ClassCastException異常。
當在構造方法中傳入Comparator的時候會覆蓋原有方法中的Comparable或Comparator。
下麵是一個例子
1 | // 自定義Person類,實現了Comparable接口,先比較age再比較name |
1 | // 測試 |
1 | Output: |
1 | // 重冩Comparator, 先按照相反的順序比較age,再比較name |
1 | Output: |
Map
Map主要是存放類似<key, value>這樣的鍵值對的數據結構。
HashMap的底層數據結構在Java8之前採用的是數組+鏈表的形式,數組的每一個元素即爲哈希桶,同一個桶中存在多個元素時(髮生哈希衝突)將同一個桶中的元素存儲在鏈表中。
Java8之後對鏈表進行了改進,當鏈表長度超過閾值(默認值8)之後鏈表會被轉化成紅黑樹,從而提高查詢效率(從O(n)提昇至O(logn))
HashMap
null值的處理
HashMap的Key和Value都可以是null(Key隻可以有一個null,Value可以有多個null)。
線程安全性
HashMap是Map接口的實現類之一。和HashTable相比HashMap不是線程安全的,並且爲了避免多線程問題帶來的問題,當遇到多線程問題時,應當使用Collections.synchronizedMap把HashMap包裝成線程安全的Map或者直接使用ConcurrentHashMap
1 | Map m = Collections.synchronizedMap(new HashMap(...)); |
下麵是一個存在線程安全問題的例子
1 | Map<String, Integer> map = new HashMap<>(); |
1 | Output: |
因爲在單獨使用HashMap的情況下,不能保証線程安全。
使用Collections.synchronizedMap包裝HashMap之後
1 | Map<String, Integer> map = Collections.synchronizedMap(new HashMap<>()); |
1 | output: |
總結:Collections.synchronizedMap包裝之後的HashMap可以保証線程安全,即在同一時間內隻能有一個對map的操作生效,不會髮生衝突,或者説所有對map的操作都是同步的,有嚴格的先後順序的。
遍曆順序可變
此外,HashMap不能保証遍曆時的順序不變(因爲Key的存儲取決於哈希值,當進行插入,刪除或者Rehashing等操作的時候會改變Key之間的相對位置,從而改變遍曆的順序)。
initial capacity 和 load factor
HashMap有兩個參數initial capacity和load factor,可以在構造函數中進行設置。
1 | HashMap() // 默認initial capacity爲16, load factor爲0.75 |
Initial capacity是哈希桶的初始數量。
load factor是負載因子,用來衡量哈希表的密度。
$$
Load \ Factor(\alpha) = \frac{Number \ of \ Elements}{Capacity \ of \ Hash \ Table}
$$
當負載因子較小時説明哈希表比較稀疏,髮生哈希碰撞的可能較小,但需要更多的內存空間。相反,負載因子過大時説明哈希表過於稠密,很容易髮生哈希碰撞,降低了查找,插入和刪除的效率,但減少了內存消耗。
在HashMap中,load factor的默認值爲0.75,意味着當HashMap的元素達到當前capacity的75%時HashMap就會自動進行Rehashing並且自動擴容爲原來的兩倍。
HashMap的基本操作(get(), put()等)的時間複雜度都是O(1),但這依賴於對兩個基本參數initial capacity和load factor的合理設置。
Fieids
HashMap的底層是一個Node<K, V>類型的數組,這個數組其實就是哈希桶,每一個桶可以存放一個Node,實際上就是鏈表(或紅黑樹)
1 | transient Node<K,V>[] table; |
Node是HashMap的一個內部類
1 | static class Node<K,V> implements Map.Entry<K,V> { |
LinkedHashMap
LinkedHashMap是HashMap的子類,在HashMap的基礎上添加了雙向鏈表來保証遍曆的順序。當在需要保証遍曆順序和插入順序相同的場景下LinkedHashMap非常合適。
accessOrder
LinkedHashMap和HashMap相比多了一個特別的構造方法
1 | LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) |
新參數accessOrder是一個佈爾值,默認爲false,表示按照插入順序進行遍曆,爲true時表示按照訪問順序排序(訪問過的元素排在末尾)。可見當按照訪問順序遍曆時非常適合用來模擬LRU緩存。
1 | import java.util.LinkedHashMap; |
removeEldestEntry會在put方法被調用時被執行,如果返回值爲true就會移除首個元素。
下麵是測試代碼
1 | LRUCache<Integer, Integer> cache = new LRUCache<>(5); |
1 | Output: |
此外,和HashMap不同的是LinkedHashMap在遍曆的時候不受capacity的影響,因爲LinkedHashMap按照雙向鏈表遍曆而不是遍曆哈希桶。
同樣的,LinkedHashMap也不是線性安全的,在多線程並髮場景下需要使用Collections.synchronizedMap()進行包裝。









